Fehler Status Verwaltung
Beurteilung des Status von Entitäten und Fehlerereignissen
Wie auf Page 2, erwähnt, sind fehlerprofile immer werken zugeordnet und folglich kann sich der Status einer entität erst ab dieser hierarchieebene ändern. Wenn ein fehlerereignis auf einer bestimmten hierarchischen ebene identifiziert und aktiviert wird, wird es an alle hierarchisch übergeordneten einheiten (ab werksebene) weitergegeben, und dies bedeutet daher, dass der Status dieser einheiten wird einheitlich geändert; dieses verhalten wird als das prinzip der hierarchischen statusweitergabe identifiziert.
Die API GET Status API ermöglicht es, den Status einer Plant, Logger und/oder Device (abhängig von der hierarchieebene und der suite).
Die besonderheit dieser API ist ihr dynamisches verhalten: Sie gibt immer die explosion aller hierarchisch niedrigeren entitäten zurück, deren Status unterscheidet sich von NORMAL, und gibt somit an, welche von aktiven fehlerereignissen betroffen sind (aber nicht den eigentlichen ereignisfehlertyp).
Nehmen wir das folgende hierarchische schema als beispiel und nehmen wir an, wir möchten den Status von Plant 1, überprüfen, um zu verstehen, ob es möglicherweise aktive fehlerereignisse gibt:
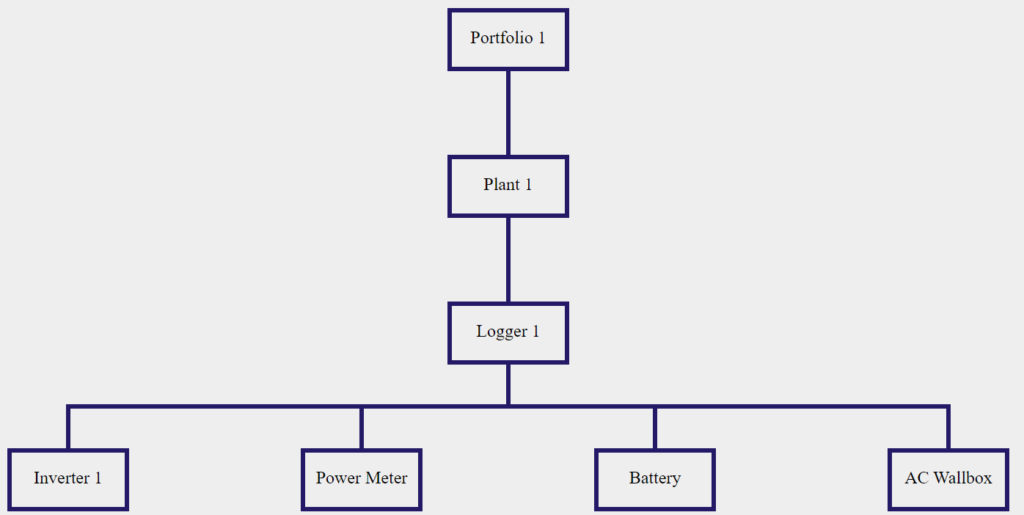
Auf der hierarchischen ebene der anlage rufen wir die API GET Plant Status auf:
https://api.auroravision.net/api/rest/v1/plant/{entityID}/status
Wenn es kein aktives fehlerereignis gibt, erhalten wir eine antwort, in der Status von Plant 1 gleich NORM (was äquivalent zu NORMAL):

Wenn es mindestens ein aktives fehlerereignis gibt, bedeutet dies, dass mindestens einem der in Plant 1, registrierten geräte, die daher hierarchische kinder von letzterem sind, ein aktives fehlerereignis zugeordnet ist; in diesem Fall passt sich die antwort der API dynamisch an, indem der Status von Plant 1 explodiert wird, aber auch von allen hierarchischen untergeordneten entitäten, deren Status ist abweichend von NORM:
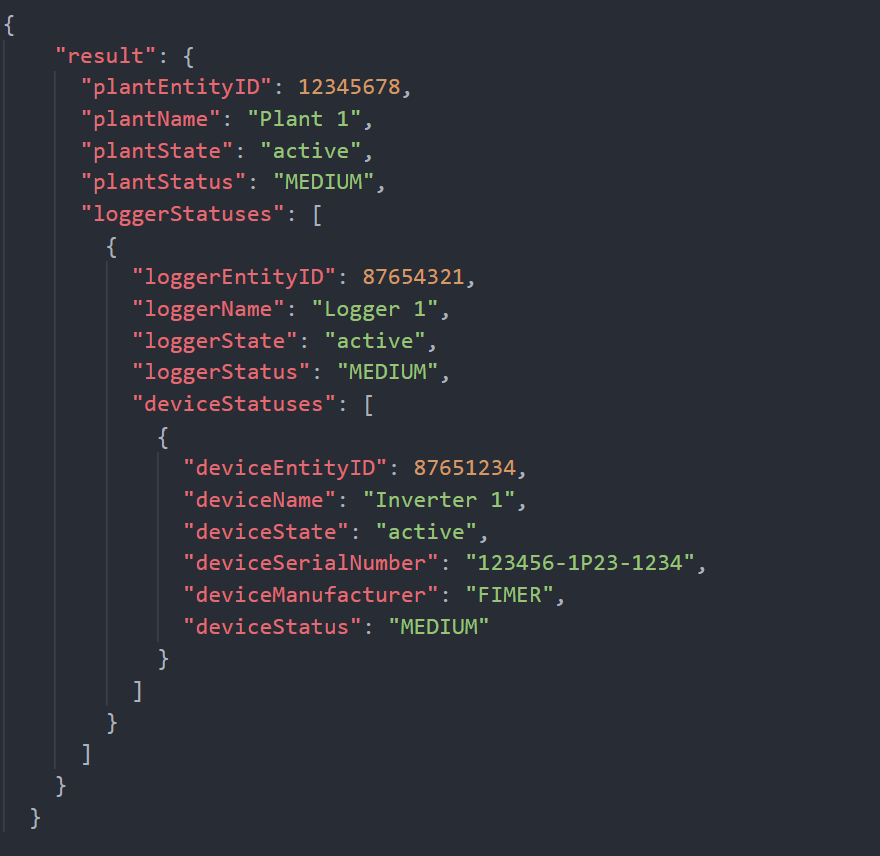
Wir können sehen, wie die Antwort jetzt strukturierter ist und wie der status von Plant 1 jetzt gleich MEDIUM, ist, ein symptom dafür, dass für einige ein fehlerereignis aktiv ist einheiten niedrigerer hierarchieebene. Dieses fehlerereignis ist für Inverter 1, aktiv, da die API uns eine explodierte antwort für alle hierarchieebenen liefert, die von Plant 1 (LVL 3) an Inverter 1 (LVL 5). Der Status aller drei entitäten ist daher gleich MEDIUM, aufgrund des prinzips der hierarchischen weitergabe, das wir oben auf der seite erwähnt haben.
Das prinzip der verarbeitung einer dynamischen antwort durch eine GET Status API ist auch auf niedrigeren hierarchieebenen vorhanden.
Wenn wir für das obige beispiel den GET Logger Status, lautet die zurückgegebene antwort:
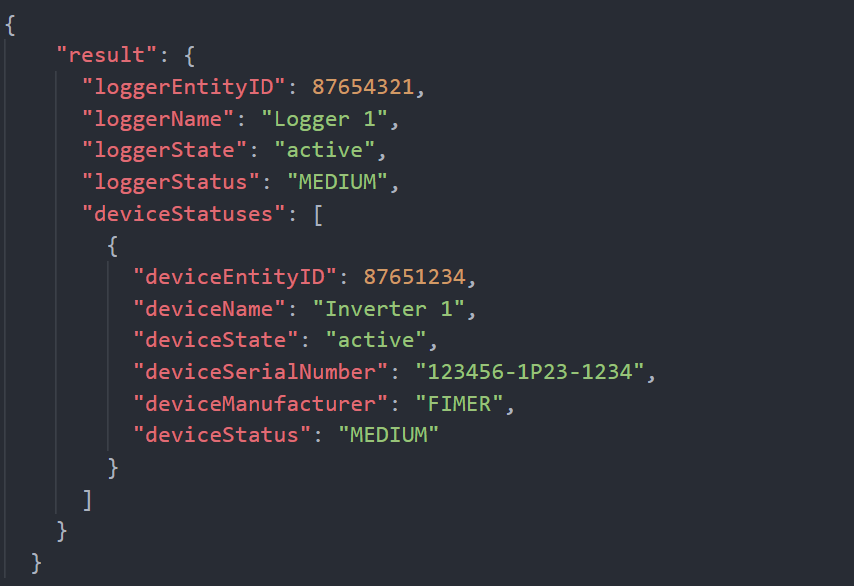
Wir können sehen, dass die antwort genau dieselbe struktur hat wie die, die mit der API GET Plant Status , erhalten wird, wobei sowohl Logger 1 als auch Inverter 1 haben ihren Status gleich MEDIUM. Der einzige unterschied ist das vorhandensein einer hierarchieebene weniger (weil wir gezielt ressourcen einer niedrigeren hierarchieebene haben).
Wir haben also gesehen, wie das prinzip der hierarchischen ausbreitung gilt: jedes gerät mit einem aktiven fehlerereignis, das dazu führt, dass sein Status sich von NORMAL, unterscheidet, ändert gleichzeitig den Status aller hierarchisch übergeordneten einheiten (ab werksebene). Dies ermöglicht es, das vorhandensein oder nichtvorhandensein von fehlern sofort zu unterscheiden, indem einfach die GET Plant Status API genutzt wird.
Natürlich sind wir, sobald wir das vorhandensein von fehlerereignissen festgestellt haben, daran interessiert zu wissen, was diese fehlerereignisse sind. Dazu können wir die API GET Events verwenden, die es ermöglicht, die fehlerereignisse einer Plant, Logger und/oder Device (abhängig von der hierarchischen ebene, an der wir interessiert sind) mit erweiterter Filterung nach: kategorie, typ, zustand und vorkommen.
Sehen wir uns die vollständige API-anfrage an und schlüsseln sie dann auf, um sie im detail zu analysieren:
https://api.auroravision.net/api/rest/v1/{plant,logger,device}/{entityID}/events?eventsKind={Profile,Source}&eventsType={eventsType}&eventsState={ALL,ACTIVE,CLOSED}&eventsOccurrence={H24,D7,D30}&page={pageNumber}
Der pfad, der es ihnen ermöglicht, auf die gewünschten ressourcen zu verweisen, erfordert immer den {entityID} und je nach hierarchieebene und der suite, auf der sie sich befinden, kann es ein Plant, Logger oder Device EID:
https://api.auroravision.net/api/rest/v1/{plant,logger,device}/{entityID}/events
Die API erfordert immer den abfrageparameter {eventsKind} um den typ der aufzurufenden fehlerereignisse zu unterscheiden.
Dieser parameter kann zwei verschiedene werte haben:
Profile: ermöglicht das abrufen von fehlerereignissen vom typ profil, i.e. solche, die von Aurora Vision basierend auf dem fehlerprofil mit seinen konfigurierten regeln aktiviert werden, die der betrachteten anlage zugeordnet sind (oder für eines der hierarchisch untergeordneten geräte)Source: ermöglicht das abrufen von fehlerereignissen vom typ quelle, i.e. maschinenfehler, die von einem gerät identifiziert wurden und welche werden dann an Aurora Vision übermittelt (das sie basierend auf dem gerät modelliert, das sie gesendet hat)
Wir haben zuvor gesagt, dass die aktivierung eines fehlers, der zu einer beliebigen kategorie gehört, die in einem fehlerprofil definiert ist, vom vorhandensein/fehlen von daten und/oder quellereignissen abhängen kann. Profile fehlerereignisse können aktiviert werden, wenn bestimmte bedingungen in den daten erkannt werden oder wenn ein gerät Aurora Vision die identifikation einer Source fehlerereignis, das in eine der profilfehlerkategorien fällt. In anbetracht dessen, dass quellereignisse schwieriger zu verstehen sind als die profilereignisse, da sie aus abkürzungen bestehen, die von gerät zu gerät unterschiedlich sein können, und dass Aurora Vision implizit die modellierung dieser ereignisse in fehlerkategorien verwaltet, um den richtigen profilfehler zu aktivieren event ist es ratsam, die API immer wie folgt zu filtern:
https://api.auroravision.net/api/rest/v1/{plant,logger,device}/{entityID}/events?eventsKind=Profile
Obwohl die restlichen queryParameters nicht erforderlich sind, um eine antwort zu erhalten, ist es bei der arbeit mit fehlerereignissen immer nützlich, typ, auftreten und zustand filtern zu können:
eventsType: ermöglicht das filtern der art von profilfehlerereignissen; es kann jeweils nur eine art von fehlerereignis gefiltert werden (eine vollständige tabelle zu den arten von fehlerereignissen finden sie auf Seite 4). Wenn nicht in die API eingefügt, werden alle ereignistypen zurückgegeben;eventsOccurrence: ermöglicht das auftreten von fehlerereignissen zu filtern; akzeptierte werte sind24H, für ein zeitfenster von 24 stunden,7D, für ein zeitfenster von 7 tagen oder, oder30D, für eine zeitfenster von 30 tagen. Wenn nicht in die API eingefügt, werden alle ereignisse zurückgegeben, die lebensdauer der anlage abdecken;eventsState: ermöglicht das filtern des Status der fehlerereignisse; akzeptierte werte sindACTIVE, für aktive ereignisse, die daher keine abschließende zeitliche singularität hatten,CLOSED, für geschlossene ereignisse, oderALL, für anfragen gleichzeitig aktive und geschlossene ereignisse. Wenn es nicht in die API eingefügt wird, werden alle aktiven und geschlossenen ereignisse zurückgegeben;
An diesem punkt haben wir alle tools, um zu verstehen, welche fehlerereignisse für Plant 1:
https://api.auroravision.net/api/rest/v1/plant/12345678/events?eventsKind=Profile&eventsOccurrence=24H&eventsState=ACTIVE
Wir haben uns auf der hierarchischen ebene plant platziert, indem wir die EID von Plant 1 (12345678), eingegeben und ACTIVE fehlerereignisse angefordert haben die letzten 24H:

Aus der antwort können wir ersehen, dass zwei profiltyp-fehlerereignisse aktiv sind: ein DEVCOM für Inverter 1 und ein LOGCOM für Logger 1. Die beiden fehlerereignisse werden zu unterschiedlichen zeitpunkten aktiviert und anhand der definitionen können wir davon ausgehen, dass Inverter 1 bei aufgehört hat zu senden Logger 1 daten an eventStart; letzteres kommunizierte immer noch korrekt mit Aurora Vision, hörte aber anschließend bei eventStart.
Das prinzip der hierarchischen statusweitergabe gilt auch für diese art von API, wodurch bestätigt wird, dass ein fehlerereignis, wenn es auf einer bestimmten hierarchischen ebene identifiziert und aktiviert wird, an alle hierarchisch übergeordneten einheiten weitergegeben wird; damit wird ein fehlerereignis, das ein gerät betrifft, auch auf der anlagenhierarchieebene angezeigt, wie wir am obigen beispiel gut erkennen können..