Gestione Stati Errore
Valutazione Stato delle Entità ed Eventi di Errore
Come accennato a Pagina 2, i profili di errore sono sempre assegnati agli impianti e, di conseguenzdi un’entità può cambiare solo da questo livello gerarchico in poi. Quando un evento di errore viene individuato e attivato ad un certo livello gerarchico, esso viene propagato a tutte le entità gerarchicamente superiori (a partire dal livello impianto) e ciò significa quindi che lo Status di queste entità è uniformemente modificato; questo comportamento è identificato come il principio della propagazione gerarchica dello stato.
L’API GET Status permette di ottenere lo Status di un Plant, Logger e/o Device (a seconda del livello gerarchico e della suite).
La particolarità di questa API è la sua risposta dinamica: restituisce sempre l’esplosione di tutte le entità gerarchicamente inferiori il cui Status è diverso da NORMAL, indicando quindi quali sono interessati da eventi di errore attivi (ma non il tipo di evento di errore).
Prendiamo come esempio il seguente schema gerarchico e supponiamo di voler controllare lo Status di Plant 1, per capire se possono esserci eventi di errore attivi:
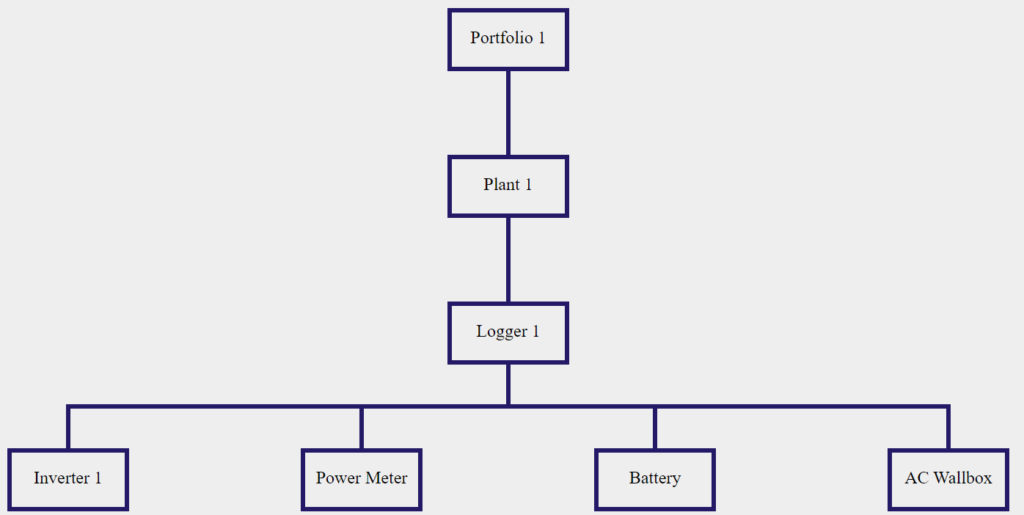
A livello gerarchico dell’impianto, chiamiamo l’API GET Plant Status :
https://api.auroravision.net/api/rest/v1/plant/{entityID}/status
Se non ci sono eventi di errore attivi, otterremo una risposta in cui lo Status di Plant 1 sarà uguale a NORM (che equivale a NORMAL):

Se è presente almeno un evento di errore attivo, significa che almeno uno dei dispositivi registrati in Plant 1, che sono quindi figli gerarchici di quest’ultimo, ha associato un evento di errore attivo; in questo caso, la risposta dell’API si adatta dinamicamente facendo esplodere lo Status di Plant 1 ma anche di tutte quelle entità figlie gerarchiche il cui Status è diverso da NORM:
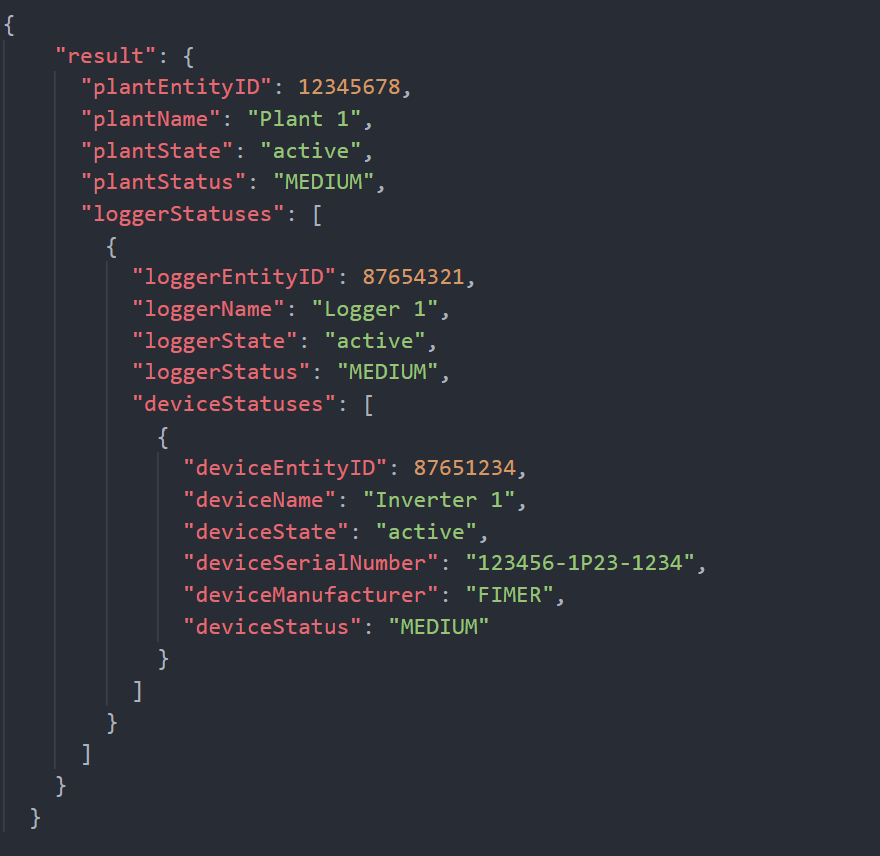
Possiamo vedere come la risposta sia ora più strutturata e come lo status di Plant 1 sia ora uguale a MEDIUM, sintomo che è attivo un evento di errore per alcune entità di livello gerarchico inferiore. Questo evento di errore è attivo per Inverter 1, perché l’API fornisce una risposta esplosa per tutti i livelli gerarchici che vanno da Plant 1 (LVL 3) ad Inverter 1 (LVL 5). Lo Status di tutte e tre le entità è quindi uguale a MEDIUM, per il principio di propagazione gerarchica di cui abbiamo parlato ad inizio pagina.
Il principio di gestione di una risposta dinamica tramite un’API GET Status API è presente anche a livelli gerarchici inferiori.
Se per l’esempio precedente chiamiamo GET Logger Status, la risposta restituita sarà:
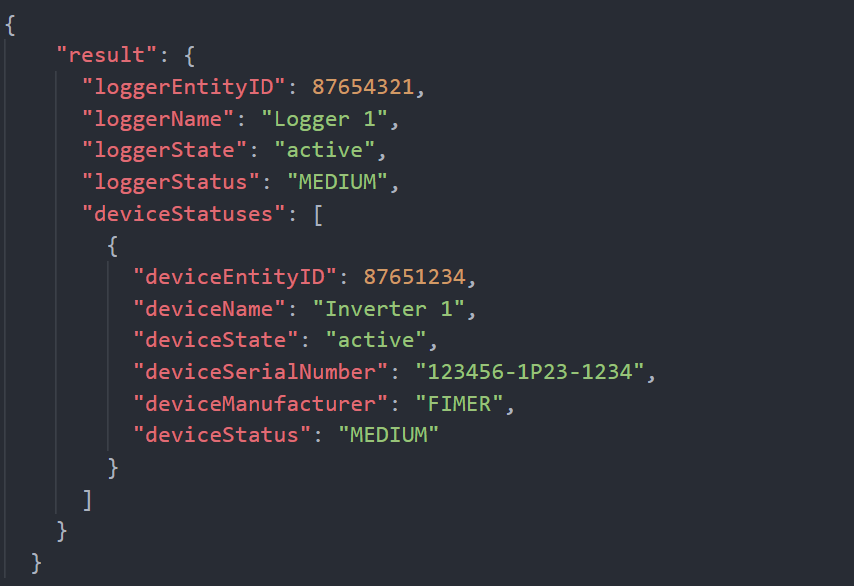
Possiamo vedere come la risposta abbia la stessa struttura di quella ottenuta con l’API GET Plant Status , dove sia Logger 1 che Inverter 1 hanno il loro Status uguale a MEDIUM. L’unica differenza è la presenza di un livello gerarchico in meno (perché abbiamo puntato risorse di un livello gerarchico inferiore).
Abbiamo quindi visto come si applica il principio della propagazione gerarchica: qualsiasi dispositivo che abbia un evento di errore attivo, che fa sì che il suo Status sia diverso da NORMAL, cambia contemporaneamente lo Status di tutte le entità gerarchicamente superiori (a partire da livello di impianto). Questo permette di discriminare immediatamente la presenza o l’assenza di errori semplicemente sfruttando l’API GET Plant Status.
Ovviamente, una volta accertata la presenza di eventi di errore, ci interessa sapere quali sono questi eventi di errore. Per farlo possiamo utilizzare l’API GET Events che permette di ottenere gli eventi di errore di un Plant, Logger e/o Device (a seconda del livello gerarchico a cui siamo interessati) con filtraggio avanzato su: categoria, tipo, stato e occorrenza.
Diamo un’occhiata alla richiesta API completa e poi analizziamola in dettaglio:
https://api.auroravision.net/api/rest/v1/{plant,logger,device}/{entityID}/events?eventsKind={Profile,Source}&eventsType={eventsType}&eventsState={ALL,ACTIVE,CLOSED}&eventsOccurrence={H24,D7,D30}&page={pageNumber}
Il path, che ti permette di puntare alle risorse desiderate, richiede sempre l’ {entityID} ed, in base al livello gerarchico e alla suite in cui ci troviamo, può essere un Plant, Logger o Device EID:
https://api.auroravision.net/api/rest/v1/{plant,logger,device}/{entityID}/events
L’API richiede sempre il parametro query {eventsKind} per discriminare la tipologia di eventi di errore da chiamare.
Questo parametro può avere due valori diversi:
Profile: permette di ottenere gli eventi di errore di tipo profilo, ovvero quelli che vengono attivati da Aurora Vision in base al profilo di errore, con le sue regole configurate, associate all’impianto considerato (o per uno dei dispositivi gerarchicamente figli di quest’ultimo)Source: permette di ottenere eventi di errore di tipo sorgente, ovvero errori macchina identificati da un dispositivo e che vengono quindi comunicati ad Aurora Vision (che li modella in base al dispositivo che li ha inviati)
In precedenza abbiamo detto che l’attivazione di un errore, appartenente a una qualsiasi categoria definita in un Profilo di Errore, può dipendere dalla presenza/assenza di dati e/o da eventi sorgente. Gli eventi di errore Profile possono essere attivati quando vengono rilevate condizioni specifiche sui dati oppure quando un dispositivo comunica ad Aurora Vision l’identificazione di un evento di errore Source che rientra in una delle categorie di errore del profilo configurato. Considerando che gli eventi sorgente sono più difficili da capire rispetto a quelli profilo, perché sono composti da abbreviazioni che possono variare da dispositivo a dispositivo, e che Aurora Vision gestisce implicitamente la modellazione di questi eventi in categorie di errore in modo da attivare l’errore di profilo corretto, è consigliabile filtrare sempre l’API come segue:
https://api.auroravision.net/api/rest/v1/{plant,logger,device}/{entityID}/events?eventsKind=Profile
Sebbene il resto dei queryParameters non sia necessario per ottenere una risposta, quando si lavora con eventi di errore è sempre utile poter filtrare tipo, occorrenza e stato:
eventsType: permette di filtrare il tipo di eventi di errore del profilo; è possibile filtrare un solo tipo di evento di errore alla volta (per una tabella completa sui tipi di eventi di errore, fare riferimento a Pagina 4). Se non inserito nell’API, verranno restituiti tutti i tipi di eventi;eventsOccurrence: permette di filtrare il verificarsi di eventi di errore; i valori accettati sono24H, fper una finestra temporale di 24 ore,7D, per una finestra temporale di 7 giorni, oppure30D, per una finestra temporale di 30 giorni. Se non inserito nell’API, verranno restituiti tutti gli eventi che coprono il ciclo di vita dell’impianto;eventsState: permette di filtrare lo stato degli eventi di errore; i valori accettati sonoACTIVE, per eventi attivi che quindi non hanno avuto una singolarità temporale di chiusura,CLOSED, per eventi chiusi, oppureALL, per richiedere eventi attivi e chiusi contemporaneamente. Se non inseriti nell’API, verranno restituiti tutti gli eventi attivi e chiusi;
A questo punto abbiamo tutti gli strumenti per capire quali eventi di errore sono attivi per Plant 1:
https://api.auroravision.net/api/rest/v1/plant/12345678/events?eventsKind=Profile&eventsOccurrence=24H&eventsState=ACTIVE
Poniamoci a livello gerarchico plant, inserendo l’EID di Plant 1 (12345678), richiedendo eventi di errore ACTIVE per le ultime 24H:

Possiamo vedere dalla risposta che sono attivi due eventi di errore del tipo di profilo: un DEVCOM per Inverter 1 ed un LOGCOM per Logger 1. I due eventi di errore vengono attivati in momenti diversi e, facendo riferimento alle definizioni, possiamo supporre che Inverter 1 abbia smesso di inviare dati a Logger 1 ad eventStart; quest’ultimo stava ancora comunicando correttamente con Aurora Vision, ma successivamente ha smesso di farlo ad eventStart.
Il principio della propagazione dello stato gerarchico vale anche per questo tipo di API, a conferma quindi che quando un evento di errore viene identificato ed attivato ad un certo livello gerarchico, esso viene propagato a tutte le entità gerarchicamente superiori; ciò significa che un evento di errore che interessa un dispositivo viene visualizzato anche a livello gerarchico dell’impianto, come possiamo chiaramente percepire dall’esempio sopra riportato.