Zarządzanie Stanem Błędów
Status Jednostek i Ocena Zdarzeń Błędów
Jak wspomniano w Strona 2, profile błędów są zawsze przypisywane do zakładów i w konsekwencji Status jednostki może się zmieniać tylko od tego poziomu hierarchicznego wzwyż. Gdy zdarzenie błędu zostanie zidentyfikowane i aktywowane na pewnym poziomie hierarchicznym, jest ono propagowane do wszystkich nadrzędnych jednostek hierarchicznie (od poziomu zakładu wzwyż) a zatem oznacza to, że Status z tych podmiotów zmienia się jednolicie; to zachowanie jest identyfikowane jako zasada hierarchicznej propagacji statusu.
Interfejs API GET Status umożliwia uzyskanie Status i Plant, Logger i/lub Device (w zależności od poziomu hierarchicznego i zestawu).
Cechy szczególne tego interfejsu API to jego dynamiczna reakcja: zawsze zwraca eksplozję wszystkich hierarchicznie niższych jednostek, których Status różni się od NORMAL, co wskazuje, na które z nich mają wpływ aktywne zdarzenia błędu (ale nie rzeczywisty typ błędu zdarzenia).
Weźmy następujący schemat hierarchiczny jako przykład i załóżmy, że chcemy saby zrozumieć, czy mogą występować jakieś aktywne zdarzenia błędów:
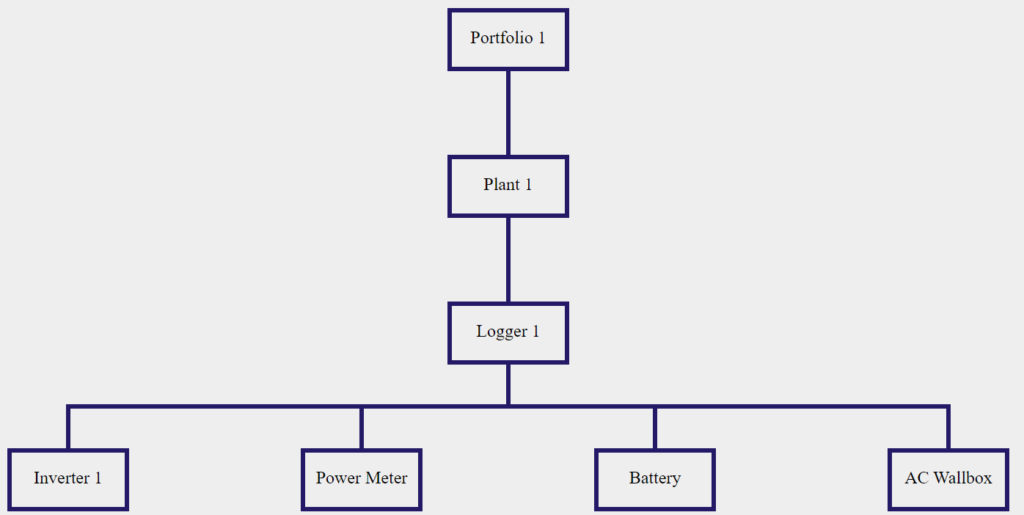
Na poziomie hierarchicznym zakładu nazwijmy GET Plant Status API:
https://api.auroravision.net/api/rest/v1/plant/{entityID}/status
Jeśli nie ma aktywnego zdarzenia błędu, otrzymamy odpowiedź, w której Status i Plant 1 będzie równy NORM (co jest równoważne z NORMAL):

Jeśli występuje przynajmniej aktywne zdarzenie błędu, oznacza to, że co najmniej jedno z urządzeń zarejestrowanych w Plant 1, które są zatem hierarchicznymi dziećmi tego ostatniego, ma powiązane aktywne zdarzenie błędu; w tym przypadku odpowiedź API dynamicznie dostosowuje się poprzez rozbicie Status i Plant 1 ale także wszystkich tych hierarchicznych jednostek podrzędnych, których Status jest różni się od NORM:
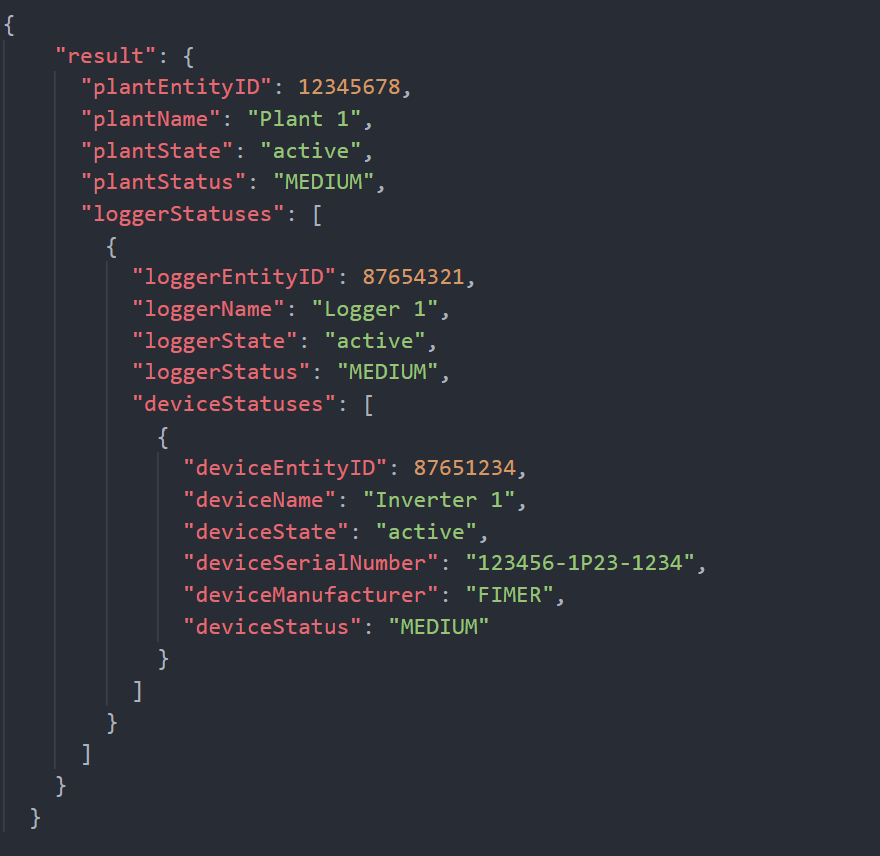
Możemy zobaczyć, jak odpowiedź jest teraz bardziej ustrukturyzowana i jak stan Plant 1 jest teraz równy MEDIUM, co jest symptomem, że zdarzenie błędu jest aktywne dla niektórych podmioty niższego poziomu hierarchicznego. To zdarzenie błędu jest aktywne dla Inverter 1, ponieważ interfejs API zapewnia nam odpowiedź eksplodującą dla wszystkich poziomów hierarchicznych, począwszy od Plant 1 (LVL 3) na Inverter 1 (LVL 5). Status wszystkich trzech encji jest zatem równy MEDIUM, ze względu na zasadę hierarchicznej propagacji, o której wspomnieliśmy na górze strony.
Zasada obsługi odpowiedzi dynamicznej przez interfejs API GET Status występuje również na niższych poziomach hierarchicznych.
Jeśli w powyższym przykładzie wywołamy funkcję GET Logger Status, zwrócona odpowiedź będzie następująca:
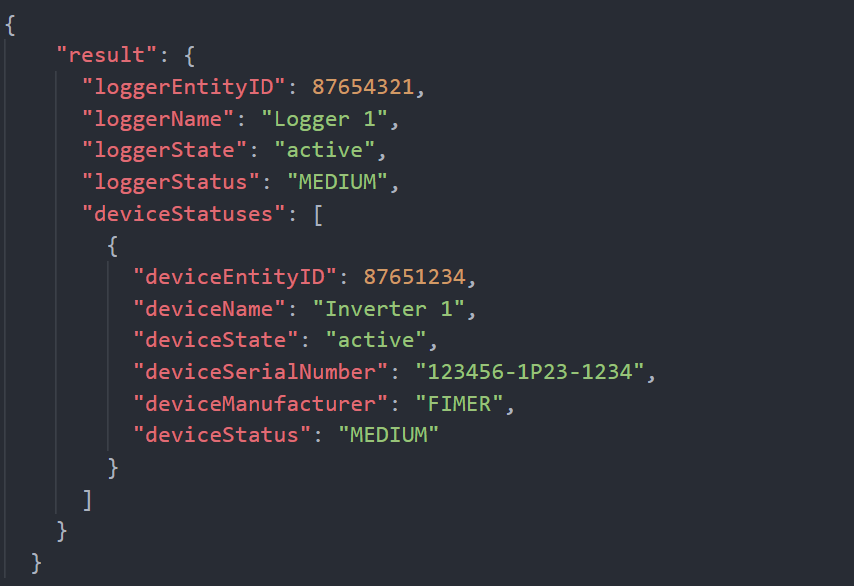
Możemy zobaczyć, jak odpowiedź ma dokładnie taką samą strukturę, jak ta uzyskana za pomocą interfejsu API GET Plant Status API, gdzie zarówno Logger 1 jak i Inverter 1 mają swój Status równy MEDIUM. Jedyną różnicą jest obecność jednego mniej hierarchicznego poziomu (ponieważ ukierunkowaliśmy zasoby niższego poziomu hierarchicznego).
Zauważyliśmy zatem, jak ma zastosowanie zasada hierarchicznej propagacji: każde urządzenie, w którym występuje aktywne zdarzenie błędu, które powoduje, że jego Status jest inny niż NORMAL, jednocześnie zmienia Status wszystkich hierarchicznie nadrzędnych jednostek (od poziomu zakładu w górę). Pozwala to natychmiast odróżnić obecność lub brak błędów, po prostu wykorzystując GET Plant Status API.
Oczywiście, po ustaleniu występowania zdarzeń błędów, jesteśmy zainteresowani poznaniem tych zdarzeń błędów. W tym celu możemy skorzystać z API GET Events które pozwala uzyskać zdarzenia błędów Plant, Logger i/lub Device (w zależności od interesującego nas poziomu hierarchii) z zaawansowanym filtrowaniem według: kategorii, typu, stanu i wystąpienia.
Spójrzmy na pełne żądanie API, a następnie podzielmy je, aby szczegółowo je przeanalizować:
https://api.auroravision.net/api/rest/v1/{plant,logger,device}/{entityID}/events?eventsKind={Profile,Source}&eventsType={eventsType}&eventsState={ALL,ACTIVE,CLOSED}&eventsOccurrence={H24,D7,D30}&page={pageNumber}
I path, która umożliwia wskazanie żądanych zasobów, zawsze wymaga {entityID} i, w zależności od poziomu hierarchii i pakietu, na którym się znajdujesz, może to być Plant, Logger lub Device EID:
https://api.auroravision.net/api/rest/v1/{plant,logger,device}/{entityID}/events
Interfejs API zawsze wymaga parametru zapytania {eventsKind} w celu rozróżnienia typu zdarzeń błędu do wywołania.
Ten parametr może mieć dwie różne wartości:
Profile: pozwala uzyskać zdarzenia błędów typu profilu, tj. te, które są aktywowane przez Aurora Vision na podstawie profilu błędu, ze skonfigurowanymi regułami, powiązanymi z rozważaną instalacją (lub dla jednego z urządzeń hierarchicznie potomnych tego ostatniego)Source: pozwala uzyskać zdarzenia błędów typu źródłowego, tj. błędy maszyny identyfikowane przez urządzenie i które są następnie przekazywane do Aurora Vision (która modeluje je na podstawie urządzenia, które je wysłało)
Powiedzieliśmy wcześniej, że aktywacja błędu należącego do dowolnej kategorii zdefiniowanej w profilu błędu może zależeć od obecności/braku danych i/lub zdarzeń źródłowych. Zdarzenia błędów Profile można aktywować, gdy określone warunki są wykrywane w danych lub gdy urządzenie komunikuje się z systemem Aurora Vision w celu identyfikacji zdarzenia błędu Source które należy do jednej z kategorii błędów profilu. Biorąc pod uwagę, że zdarzenia źródłowe są trudniejsze do zrozumienia niż te profilowe, ponieważ składają się ze skrótów, które mogą się różnić w zależności od urządzenia, a Aurora Vision pośrednio zarządza modelowaniem tych zdarzeń w kategoriach błędów, aby aktywować prawidłowy błąd profilu zdarzenia, zaleca się zawsze filtrować API w następujący sposób:
https://api.auroravision.net/api/rest/v1/{plant,logger,device}/{entityID}/events?eventsKind=Profile
Chociaż pozostałe queryParameters nie są wymagane do uzyskania odpowiedzi, podczas pracy ze zdarzeniami błędów zawsze przydatna jest możliwość filtrowania typu, wystąpienia i stanu:
eventsType: umożliwia filtrowanie typu zdarzeń błędów profilu; tylko jeden typ zdarzenia błędu może być filtrowany na raz (pełną tabelę typów zdarzeń błędu można znaleźć na Strona 4). eśli nie zostanie wstawiony do API, zwrócone zostaną wszystkie typy zdarzeń;eventsOccurrence: umożliwia filtrowanie występowania zdarzeń błędów; akceptowane wartości to24H, dla okna czasowego 24 godzin,7D, dla okna czasowego 7 dni, lub30D, dla czasu okno 30 dni. Jeśli nie zostanie wstawiony do API, zwrócone zostaną wszystkie zdarzenia, które obejmują czas życia zakładu;eventsState: pozwala filtrować stan zdarzeń błędów; akceptowane wartości toACTIVE, fdla aktywnych zdarzeń, które w związku z tym nie miały zamykającej czasowej osobliwości,CLOSED, dla zdarzeń zamkniętych, lubALL, dla żądania imprezy aktywne i zamknięte w tym samym czasie. Jeśli nie zostanie wstawiony do API, wszystkie aktywne i zamknięte zdarzenia zostaną zwrócone;
W tym momencie mamy wszystkie narzędzia, aby zrozumieć, które zdarzenia błędów są aktywne dla Plant 1:
https://api.auroravision.net/api/rest/v1/plant/12345678/events?eventsKind=Profile&eventsOccurrence=24H&eventsState=ACTIVE
Umieściliśmy się na poziomie hierarchicznym plant, wprowadzając EID EID i Plant 1 (12345678), żądając zdarzeń błędów ACTIVE w ostatnie 24H:

Na podstawie odpowiedzi widzimy, że dwa zdarzenia błędu typu profilu są aktywne: a DEVCOM dla Inverter 1 i LOGCOM dla Logger 1. Dwa zdarzenia błędów są aktywowane w różnych momentach i, odnosząc się do definicji, możemy założyć, że Inverter 1 przestał wysyłać dane do Logger 1 w eventStart; ten ostatni nadal poprawnie komunikował się z Aurora Vision, ale później przestał to robić na eventStart.
Zasada hierarchicznej propagacji statusu obowiązuje również dla tego typu API, co potwierdza, że gdy zdarzenie błędu zostanie zidentyfikowane i aktywowane na pewnym poziomie hierarchicznym, jest ono propagowane do wszystkich hierarchicznie nadrzędnych jednostek; oznacza to, że zdarzenie błędu, które ma wpływ na urządzenie, jest również wyświetlane na poziomie hierarchicznym zakładu, co wyraźnie widać na powyższym przykładzie.