Telemetriedaten
Timeseries APIs
Timeseries APIs werden hauptsächlich verwendet, wenn sie für einen bestimmten datentyp einen detaillierten trend erhalten möchten, der es ihnen ermöglicht, echtzeitanalysen und-darstellungen für ein benutzerdefiniertes Zeitfenster durchzuführen.
Diese art von APIs sind immer wie folgt strukturiert:

Der path, mit dem sie auf die gewünschten ressourcen zeigen können, erfordert immer die folgenden parameter:
{power,frequency,wind,temperature,voltage,current,energy,kpis}:der ressourcentyp, auf den verwiesen werden soll. Dieser parameter gibt nicht die eigentlichen daten an, die sie erhalten möchten, sondern die allgemeine kategorie, zu der die gewünschten daten gehören (bitte beachten sie, dass ein API-Aufruf jeweils nur eine kategorie akzeptiert, es ist derzeit nicht möglich, BULK-Aufrufe durchzuführen);{entityID}: es kann sich um eine anlagen-oder Geräte-EID handeln. Im ersten fall berücksichtigt der erhaltene wert die aggregation aller geräte, für die dieser wert existiert, auf anlagenebene; im zweiten fall bezieht sich der erhaltene wert auf das einzelne interessierende gerät;{dataType}: stellt die tatsächlich zu erhaltenden daten dar. Die verfügbarendataTypesvariieren je nach ressource, auf die verwiesen wird, eine detaillierte beschreibung ist direkt in der OpenAPIs Swagger;{valuetype}: stellt die art des aggregationskriteriums dar, mit dem die angeforderten daten vorliegen zu erhalten.
Die queries, mit denen sie die angeforderten daten filtern können, erfordern immer die folgenden parameter:
{sampleSize}: definiert die abtastrate, mit der daten abgerufen werden. Je länger die abtastrate, desto kürzer die länge des als antwort erhaltenen datenarrays (asampleTimegleichMin5hat mehr Samples im Antwortarray als einsampleTimegleichMin15);{startDate}: die untere grenze, die es ermöglicht, den beginn des interessierenden zeitfensters zu definieren. Sein Format ist immerYYYYMMGG(eg: 20220321);{endDate}: die obergrenze, die es erlaubt definieren sie das ende des interessierenden zeitfensters. Sein format ist immerYYYYMMGG(eg: 20220322) und muss zeitlich nach dem{startDate}liegen;{timezone}: ermöglicht es, den API-Aufruf zu einer korrekten datenwiederherstellung gemäß der angeforderten zeitzone zu leiten.
Ein Timeseries-Aufruf liefert normalerweise ein array von werten als antwortarray of values as response.
Die länge des arrays hängt direkt vom {sampleSize} wert und vom durch {startDate} und {endDate} definierten zeitfenster ab. Sobald ein referenzzeitfenster definiert wurde, wird der wert {sampleSize} dieses fenster mehr oder weniger häufig aufteilen, wodurch folglich die länge des arrays als antwort geändert wird: je größer der {sampleSize} desto spärlicher wird das zeitfenster aufgeteilt, was zu weniger elementen im antwortarray führt.
Es lohnt sich, sich ein direktes beispiel anzusehen, um diese konzepte besser zu erklären.
Beispiel
Nehmen wir an, wir möchten den echtzeittrend der von einem wechselrichter während des aktuellen tages erzeugten leistung darstellen (suppose we are in the spring equinox). The best solution is to use a Timeseries API, which will have the following general structure:
https://api.auroravision.net/api/rest/v1/stats/{power,frequency,wind,temperature,voltage,current,energy,kpis}/timeseries/12345678/{dataType}/{valueType}?{sampleSize}&{startDate}&{endDate}&{timeZone}
Innerhalb der obigen generischen struktur wissen wir folgendes:
- Die anzustrebende ressourcenkategorie ist
{power}und innerhalb dieser kategorie{dataType}istGenerationPower; - Der aufzurufende
{valueType}Maximum,MinimumundAverage(siehe detaillierte analyse weiter unten); - Das zeitfenster ist der tag der frühlings-tagundnachtgleiche, also
{startDate}ist 20220321 und{endDate}ist 20220322;
Dies führt dazu, dass unser aufruf die folgende form annimmt:
https://api.auroravision.net/api/rest/v1/stats/power/timeseries/12345678/GenerationPower/average?{sampleSize}&startDate=20220321&endDate=20220322&{timeZone}
Der parameter {sampleSize} kann die folgenden werte haben:
Min5: das zeitfenster wird alle 5 minuten geschnitten, wobei jede einzelne probe genommen wird, die auf Aurora Vision gespeichert ist (iehe Seite 1);Min15: das zeitfenster wird alle 15 minuten geschnitten, 3 Aurora Vision-samples sind für jede scheibe enthalten;Min30: das zeitfenster wird alle 30 minuten geschnitten, 6 Aurora Vision-samples sind für jede scheibe enthalten;Hour: das zeitfenster wird alle 60 minuten geschnitten, 12 Aurora Vision-samples sind für jede scheibe enthalten;Day: das zeitfenster wird jeden tag geschnitten, 288 Aurora Vision-samples sind für jeden scheibe enthalten;Month: das zeitfenster wird jeden monat aufgeteilt;Year: das zeitfenster wird jedes jahr aufgeteilt.
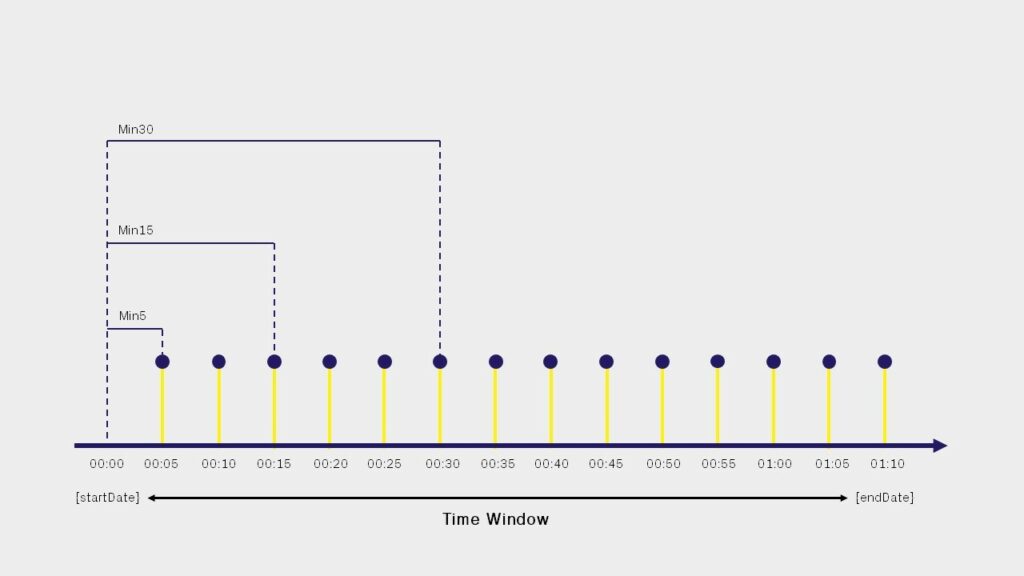
Da wir daran interessiert sind, den leistungstrend so oft wie möglich in echtzeit darzustellen, setzen wir {sampleSize} auf Min5 (es wäre nicht sinnvoll, einen wert einzugeben, der größer ist als der des gewählten zeitfensters) und den parameter {timeZone} auf Europe/Rome zu setzen:
https://api.auroravision.net/api/rest/v1/stats/power/timeseries/12345678/GenerationPower/average?sampleSize=Min5&startDate=20220321&endDate=20220322&timeZone=Europe/Rome
Die antwort wird ein array einer bestimmten länge sein, in dem jedes element immer aus der folgenden struktur besteht:

Wie wir sehen können, besteht die antwort aus:
Start: stellt die Epoch dar, die der zeitwert in UTC ist; ändert sich gemäß dertimeZone(verschiedene zeitzonen haben unterschiedliche epochen für denselben leistungswert) und folgt den durchsampleSizedefinierten zeitlichen abschnitten;Units: stellt die maßeinheit dar;Value: stellt den wert dar.
Extrapolieren wir einen größeren auszug aus der antwort:

Da feld start erhöht sich von element zu element und geht von einem wert von 1647875700 zu einem wert von 1647876000 über; Wenn wir die differenz zwischen den beiden Epoch machen, erhalten wir genau 5 minuten oder anders ausgedrückt den wert, den wir für den parameter sampleSize eingestellt haben.
Von epoch 1647876000 die felder start und value existieren nicht mehr; denn unter der annahme, dass der anruf vor 16:20 (Europe/Rome) erfolgt ist,
Da feld start erhöht sich von element zu element und geht von einem wert von 1647875700 zu einem wert von 1647876000 über; Wenn wir die differenz zwischen den beiden Epoch machen, erhalten wir genau 5 minuten oder anders ausgedrückt den wert, den wir für den parameter sampleSize eingestellt haben.
Von epoch 1647876000 die felder start und value existieren nicht mehr; denn unter der annahme, dass der anruf vor 16:20 (Europe/Rome) erfolgt ist,liegt das mit dieser Epoch bezeichnete sample in der zukunft und existiert daher noch nicht. Als solches stellt Aurora Vision das feld innerhalb des Elements nicht bereit; Bei einem neuen anruf nach 16:20 wird es jedoch bereitgestellt, da es ausgefüllt wurde.
Das prinzip des vorhandenseins/fehlens bestimmter felder in den antwortelementen einer zeitreihen-API (in den letzten zeilen des obigen beispiels ausgedrückt) ist von grundlegender bedeutung: es gilt nicht nur in. Bei zukünftigen mustern, aber auch und vor allem bei völligem fehlen von daten zu Aurora Vision. Dies ermöglicht es, den von den Telemetrie-APIs erhaltenen antworten kohärenz zu verleihen, denn wenn der value abgelegt ist, bedeutet dies, dass dieser wert tatsächlich auf Aurora Vision vorhanden ist, andernfalls wäre er nicht vorhanden.
Wie bei aggregierten aufrufen ist auch bei zeitreihenaufrufen der Parameter {valuetype} on großer bedeutung, da er je nach ressourcenkategorie, also {dataType}, zu erhalten und wird auch von {sampleSize} beeinflusst.
Für einen {dataType} der zur kategorie {power,frequency,wind,temperature,voltage,current,kpis} gehört, wird der {valueType} annehmen kann drei verschiedene werte:
Maximum: gibt den maximalen wert zurück, der unter allen samples in jedem zeitabschnitt gefunden wurde, bestimmt durch den{sampleSize}, wert im definierten{startDate}und{endDate}zeitfenster, für den angeforderten{dataType};Minimum: gibt den kleinsten wert zurück, der unter allen samples in jedem zeitabschnitt gefunden wurde, bestimmt durch den{sampleSize}, wert im definierten{startDate}und{endDate}zeitfenster, für den angeforderten{dataType};Average: gibt den durchschnittswert aller samples in jedem zeitabschnitt zurück, bestimmt durch den{sampleSize}, wert im definierten{startDate}und{endDate}zeitfenster, für den angeforderten{dataType}
HINWEIS: für die kategorie kpis, gelten die obigen Überlegungen nur, wenn Power-Based KPIs genannt werden. Weitere einzelheiten finden sie unter OpenAPIs Swagger.
Werfen wir einen blick auf einige anwendungsfälle, in denen wir eine anlage ( entityID: 12345678 ) mit einem einzelnen registrierten wechselrichtergerät ( entityID: 87654321 ):
Anwendungsfall 1
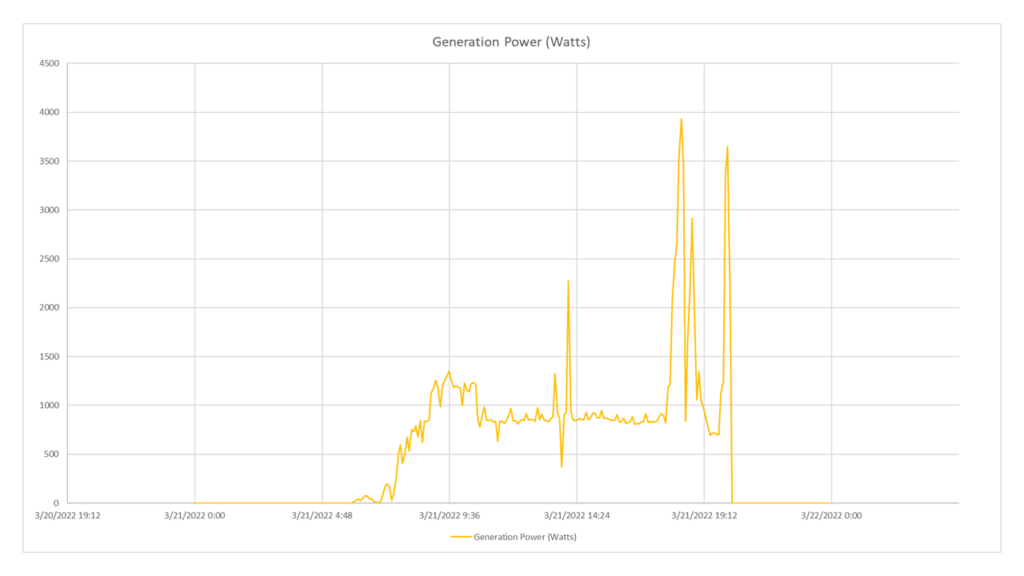
Ich möchte den vom wechselrichter erzeugten strom alle 5 minuten am tag der frühlings-Tagundnachtgleiche in echtzeit abrufen. auf diese weise kann ich den Trend darstellen und spezifische analysen dazu durchführen.
Problemanalyse
Wenn man bedenkt, dass das verhältnis zwischen anlage und registrierten geräten 1:1 ist, kann ich gleichgültig die entityID von einem der beiden eingeben. Ich möchte, dass der strom produziert wird, also werde ich auf die ressourcen der Kategorie power erweisen und die GenerationPower. Der parameter sampleSize ist gleich Min5 , da ich jedes einzelne sample erhalten möchte. Der Parameter valueType kann nur in diesem fall wegen der zeit gleichgültig als Maximum, Minimum oder Average gesetzt werden das fenster wird so aufgeteilt, dass es für jeden schnitt ein einzelnes sample hat, und daher macht kein tatsächlicher vorgang einen unterschied, wenn es ein einzelnes sample als referenz gibt.
Request
GET https://api.auroravision.net/api/rest/v1/stats/power/timeseries/12345678/GenerationPower/average?sampleSize=Min5&startDate=20220321&endDate=20220322&timeZone=Europe/Rome
Charted Response
Anwendungsfall 2
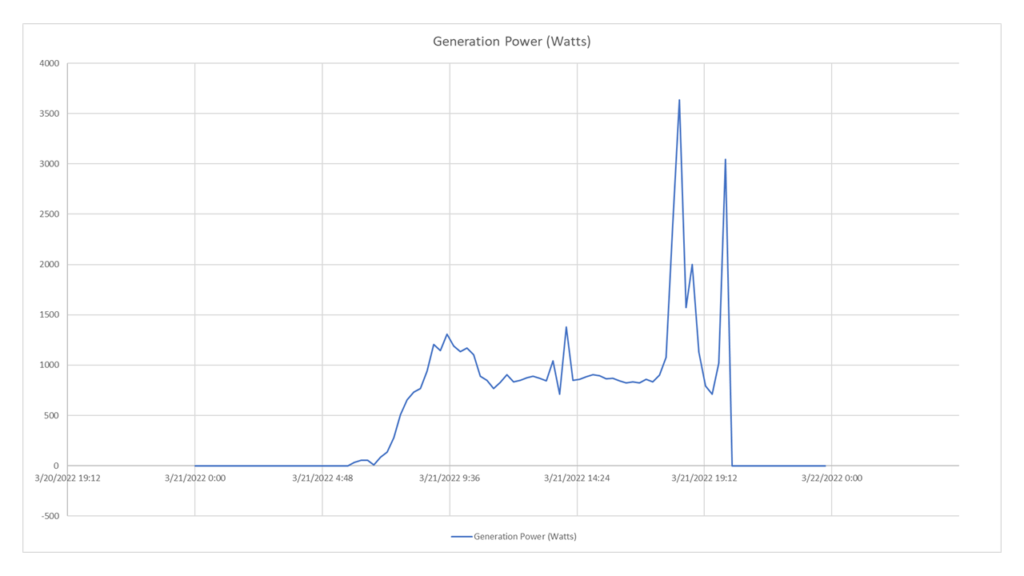
Ich möchte die durchschnittliche leistung abrufen, die der wechselrichter alle 15 minuten am tag der frühlings-tagundnachtgleiche erzeugt. Auf diese weise kann ich den trend darstellen und spezifische analysen dazu durchführen.
Problemanalyse
Wenn man bedenkt, dass das verhältnis zwischen anlage und registrierten geräten 1:1 ist, kann ich gleichgültig die entityID von einem der beiden eingeben. Ich möchte, dass der strom produziert wird, also werde ich auf die ressourcen der Kategorie power erweisen und die GenerationPower. Der parameter sampleSize ist gleich Min15. Der parameter valueType muss Average sein, da das zeitfenster so aufgeteilt wird, dass es 3 abtastwerte für jeden abschnitt hat und daher der mittelwert für die 3 abtastwerte durchgeführt wird die zu jedem slice gehören.
Request
GET https://api.auroravision.net/api/rest/v1/stats/power/timeseries/12345678/GenerationPower/average?sampleSize=Min15&startDate=20220321&endDate=20220322&timeZone=Europe/Rome
Charted Response
Für einen {dataType} der zur kategorie {energy,kpis}, gehört, kann der {valueType} zwei unterschiedliche werte annehmen:
Cumulative: gibt den letzten kumulativen wert zurück, der in jedem zeitabschnitt verfügbar ist, bestimmt durch den wert{sampleSize}, im definierten{startDate}und{endDate}zeitfenster, für den angeforderten{dataType};Delta: gibt das zurück unterschied zwischen dem letzten und dem ersten kumulativen wert, der in jedem zeitabschnitt verfügbar ist, bestimmt durch den wert{sampleSize}, im definierten{startDate}und{endDate}zeitfenster, für den angeforderten{dataType};
HINWEIS: für die kategorie kpis, gelten die obigen Überlegungen nur, wenn Energy-Based KPIs genannt werden. Weitere einzelheiten finden sie unter OpenAPIs Swagger.
Werfen wir einen blick auf einige anwendungsfälle, in denen wir eine anlage ( entityID: 12345678 ) mit einem einzelnen registrierten wechselrichtergerät ( entityID: 87654321 ):
Anwendungsfall 1
Ich möchte die vom wechselrichter erzeugte energie alle 5 minuten am tag der frühlings-tagundnachtgleiche in echtzeit abrufen; um den energietrend aufzuzeichnen.
Problemanalyse
Wenn man bedenkt, dass das verhältnis zwischen anlage und registrierten geräten 1:1 ist, kann ich gleichgültig die entityID von einem der beiden eingeben. Ich möchte die erzeugte energie, also zeige ich die ressourcen der kategorie energy und fordere die GenerationEnergy. Der parameter sampleSize ist gleich Min5 , da ich jedes einzelne sample erhalten möchte. Der parameter valueType ist gleich delta da das zeitfenster so unterteilt wird, dass es für jeden abschnitt ein einzelnes sample und daher die differenz zwischen den samples gibt liefert die in den 5 minuten tatsächlich erzeugte energie.
Request
GET https://api.auroravision.net/api/rest/v1/stats/energy/timeseries/12345678/GenerationEnergy/delta?sampleSize=Min5&startDate=20220321&endDate=20220322&timeZone=Europe/Rome
Response

Anwendungsfall 2
Ich möchte die vom wechselrichter erzeugte energie für jeden tag der woche der frühlings-tagundnachtgleiche abrufen, um den wöchentlichen energietrend aufzuzeichnen.
Problemanalyse
Wenn man bedenkt, dass das verhältnis zwischen anlage und registrierten geräten 1:1 ist, kann ich gleichgültig die entityID von einem der beiden eingeben. Ich möchte, dass die energie an jedem einzelnen tag der woche der frühlings-tagundnachtgleiche erzeugt wird, also werde ich auf die ressourcen der kategorie energy verweisen und die GenerationEnergy. Der parameter sampleSize ist gleich Day, weil ich das zeitfenster jeden einzelnen tag der woche aufteilen möchte. Der parameter valueType ist gleich delta da das zeitfenster so unterteilt ist, dass die differenz zwischen dem ersten und dem letzten abtastwert jedes wochentags (zeitfenster).
Request
GET https://api.auroravision.net/api/rest/v1/stats/energy/timeseries/87654321/GenerationEnergy/delta?sampleSize=Day?startDate=20220321&endDate=20220327&timeZone=Europe/Rome
Response
