Gestión Estado Error
Estado de Entidades y Evaluación de Eventos de Error
Como se mencionó en la Página 2,los perfiles de error siempre se asignan a las plantas y, en consecuencia, el Status de una entidad solo puede cambiar a partir de este nivel jerárquico. Cuando se identifica y activa un evento de error en un determinado nivel jerárquico, se propaga a todas las entidades jerárquicamente superiores (desde el nivel de planta en adelante) y esto significa que el Status de estas entidades cambia uniformemente; este comportamiento se identifica como el principio de propagación de estado jerárquico.
La API GET Status API permite obtener el Status ode una Plant, Logger y/o Device (dependiendo del nivel jerárquico y de la suite).
La peculiaridad de esta API es su respuesta dinámica: siempre devuelve la explosión de todas las entidades jerárquicamente inferiores cuyo Status es diferente de NORMAL, lo que indica cuáles se ven afectados por eventos de error activos (pero no el tipo de error de evento real).
omemos el siguiente esquema jerárquico como ejemplo y supongamos que queremos verificar el Status de la Plant 1, para comprender si puede haber algún evento de error activo:
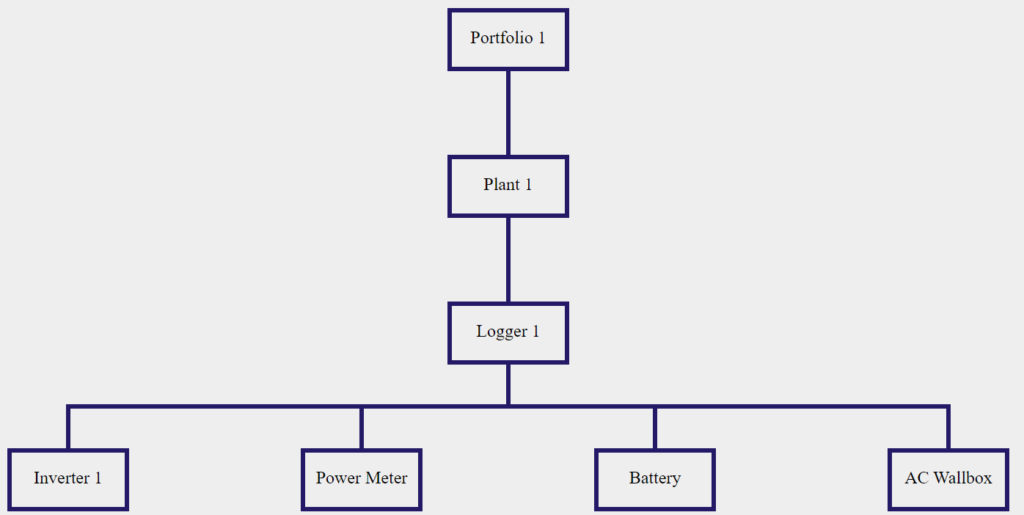
En el nivel jerárquico de la planta, llamemos a la API GET Plant Status :
https://api.auroravision.net/api/rest/v1/plant/{entityID}/status
Si no hay un evento de error activo, obtendremos una respuesta en la que el Status de Plant 1 será igual a NORM (que es equivalente a NORMAL):

Si existe al menos un evento de error activo, significa que al menos uno de los dispositivos registrados en la Plant 1, que por tanto son hijos jerárquicos de esta última, tiene asociado un evento de error activo; en este caso, la respuesta de la API se adapta dinámicamente explotando el Status de la Plant 1 pero también de todas aquellas entidades secundarias jerárquicas cuyo Status es diferente de NORM:
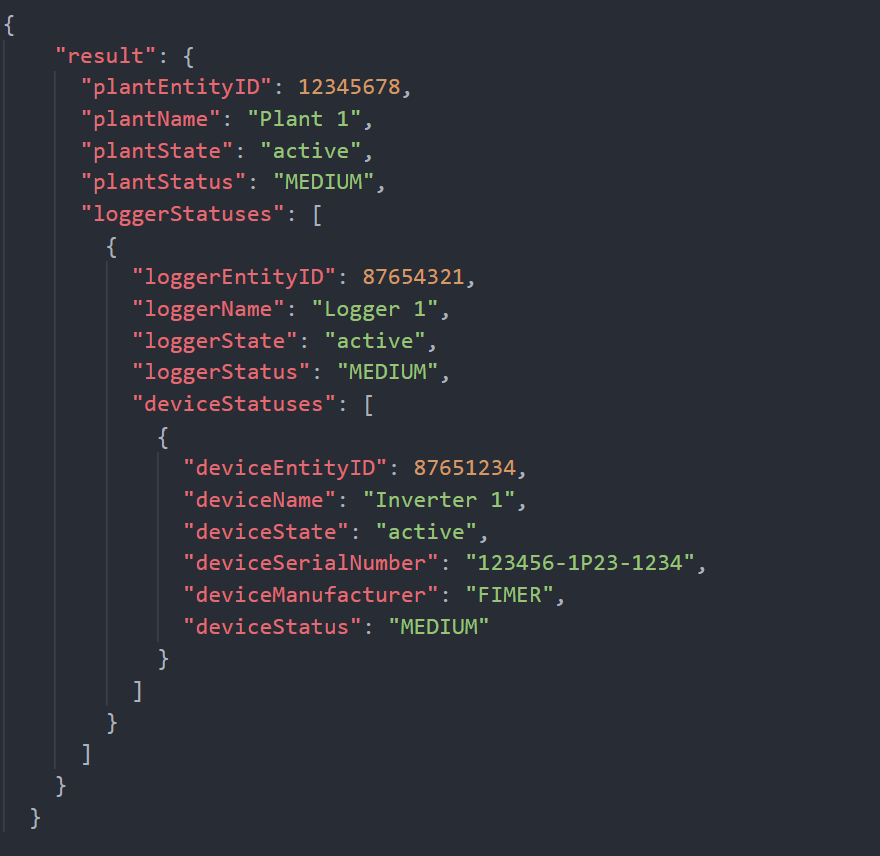
Podemos ver como la respuesta ahora está más estructurada y como el Status de la Plant 1 ahora es igual a MEDIUM, síntoma de que algún evento de error está activo para algunos entidades de menor nivel jerárquico. Este evento de error está activo para Inverter 1, porque la API nos proporciona una respuesta ampliada para todos los niveles jerárquicos que van desde Plant 1 (LVL 3) al Inverter 1 (LVL 5). Por lo tanto, el Status de las tres entidades es igual a MEDIUM, debido al principio de propagación jerárquica que mencionamos en la parte superior de la página.
El principio de manejar una respuesta dinámica por una API GET Status también está presente en los niveles jerárquicos más bajos.
Si para el ejemplo anterior vamos a llamar al GET Logger Status, la respuesta devuelta será:
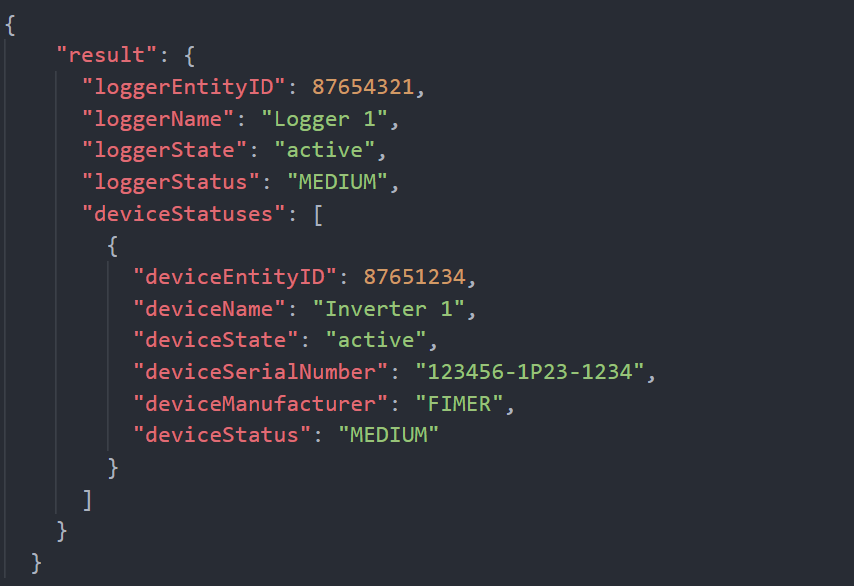
Podemos ver como la respuesta tiene exactamente la misma estructura que la obtenida con la API GET Plant Status , donde tanto Logger 1 como Inverter 1 tienen su Status igual a MEDIUM. La única diferencia es la presencia de un nivel jerárquico menos (porque tenemos recursos específicos de un nivel jerárquico más bajo).
Por lo tanto, hemos visto cómo se aplica el principio de propagación jerárquica: cualquier dispositivo que tenga un evento de error activo, que provoque que su Status sea diferente de NORMAL, cambia simultáneamente el Status de todas las entidades jerárquicamente superiores (desde el nivel de planta en adelante). Esto permite discriminar inmediatamente la presencia o ausencia de errores simplemente explotando la API GET Plant Status.
Obviamente, una vez que hemos comprobado la presencia de eventos de error, nos interesa saber cuáles son esos eventos de error. Para ello podemos utilizar la API GET Events que permite obtener los eventos de error de una Plant, Logger y/o Device (dependiendo del nivel jerárquico que nos interese) con filtrado avanzado en: categoría, tipo, estado y ocurrencia.
Echemos un vistazo a la solicitud de API completa y luego dividámosla para analizarla en detalle:
https://api.auroravision.net/api/rest/v1/{plant,logger,device}/{entityID}/events?eventsKind={Profile,Source}&eventsType={eventsType}&eventsState={ALL,ACTIVE,CLOSED}&eventsOccurrence={H24,D7,D30}&page={pageNumber}
El path, que le permite apuntar a los recursos deseados, siempre requiere el {entityID} y, según el nivel jerárquico y la suite en la que se encuentre, puede ser un Plant, Logger o Device EID:
https://api.auroravision.net/api/rest/v1/{plant,logger,device}/{entityID}/events
La API siempre requiere el parámetro de consulta {eventsKind} para discriminar el tipo de eventos de error a llamar.
Este parámetro puede tener dos valores diferentes:
Profile: permite obtener eventos de error tipo perfil, es decir, aquellos que son activados por Aurora Vision en base al perfil de error, con sus reglas configuradas, asociado a la planta considerada (o para uno de los dispositivos jerárquicamente hijos de este último)Source: permite obtener eventos de error de tipo fuente, es decir, errores de máquina identificados por un dispositivo y que luego se comunican a Aurora Vision (que los modela en función del dispositivo que los envió)
Dijimos anteriormente que la activación de un error, perteneciente a cualquier categoría definida en un Perfil de Error, puede depender de la presencia/ausencia de datos y/o eventos fuente. Los eventos de error de Profile se pueden activar cuando se dan condiciones específicas se detectan en los datos o cuando un dispositivo comunica a Aurora Vision la identificación de un evento de error Source que cae en una de las categorías de error de perfil. Teniendo en cuenta que los eventos de origen son más difíciles de entender que los de perfil, porque están compuestos por abreviaturas que pueden variar de un dispositivo a otro, y que Aurora Vision gestiona implícitamente el modelado de estos eventos en categorías de error para activar el error de perfil correcto. evento, es recomendable siempre filtrar la API de la siguiente manera:
https://api.auroravision.net/api/rest/v1/{plant,logger,device}/{entityID}/events?eventsKind=Profile
Aunque el resto de los queryParameters no son necesarios para obtener una respuesta, cuando se trabaja con eventos de error siempre es útil poder filtrar tipo, ocurrencia y estado:
eventsType: permite filtrar el tipo de eventos de error de perfil; solo se puede filtrar un tipo de evento de error a la vez (para obtener una tabla completa sobre los tipos de eventos de error, consulte la Página 4). Si no se inserta en la API, se devolverán todos los tipos de eventos;eventsOccurrence: permite filtrar la ocurrencia de eventos de error; los valores aceptados son24H, para una ventana de tiempo de 24 horas,7D, para una ventana de tiempo de 7 días, o30D, para una ventana de tiempo de 30 días. Si no se inserta en la API, se devolverán todos los eventos que cubren la vida útil de la planta;eventsState: permite filtrar el estado de los eventos de error; los valores aceptados sonACTIVE, para eventos activos que por tanto no tuvieron una singularidad temporal de cierre,CLOSED, para eventos cerrados, oALL, para solicitar eventos activos y cerrados al mismo tiempo. Si no se inserta en la API, se devolverán todos los eventos activos y cerrados;
En este punto, tenemos todas las herramientas para comprender qué eventos de error están activos para Plant 1:
https://api.auroravision.net/api/rest/v1/plant/12345678/events?eventsKind=Profile&eventsOccurrence=24H&eventsState=ACTIVE
Nos ubicamos en el nivel jerárquico planta, ingresando el EID de Plant 1 (12345678), solicitando eventos de error ACTIVE en las últimas 24H:

Podemos ver en la respuesta que dos eventos de error de tipo de perfil están activos: un DEVCOM para Inverter 1 y un LOGCOM para Logger 1. Los dos eventos de error se activan en momentos diferentes y, en referencia a las definiciones, podemos suponer que Inverter 1 dejó de enviar datos al Logger 1 en eventStart; este último todavía se comunicaba correctamente con Aurora Vision, pero posteriormente dejó de hacerlo en eventStart.
El principio de propagación jerárquica de estados también es válido para este tipo de API, confirmando así que cuando se identifica y activa un evento de error en un determinado nivel jerárquico, se propaga a todas las entidades jerárquicamente superiores; esto significa que un evento de error que afecta a un dispositivo también se muestra a nivel jerárquico de la planta, como podemos percibir claramente en el ejemplo anterior.