Données de Télémétrie
Timeseries APIs
Les API Timeseries sont principalement utilisées lorsque vous souhaitez obtenir, pour un certain type de données, une tendance détaillée, ce qui vous permet d’effectuer des analyses et des représentations en temps réel, pour une fenêtre de temps personnalisée.
Ces types d’API sont toujours structurés comme suit:

Le path, qui permet de pointer vers les ressources souhaitées, nécessite toujours les paramètres suivants:
{power,frequency,wind,temperature,voltage,current,energy,kpis}:{entityID}:;{dataType}:dataTypesOpenAPIs Swagger;{valuetype}:.
Les requêtes, qui permettent de filtrer les données demandées, nécessitent toujours les paramètres suivants:
{sampleSize}: définit le taux d’échantillonnage avec lequel obtenir les données. Plus le taux d’échantillonnage est long, il raccourcit la longueur du tableau de données obtenu en réponse (unsampleTimeégal àMin5aura plus d’échantillons dans le tableau de réponse qu’unsampleTimeégal àMin15);{startDate}:YYYYMMGG(eg: 20220321);{endDate}:YYYYMMGG(eg: 20220322) et il doit être temporellement postérieur au{startDate};{timezone}:
Un appel timeseries fournit généralement un tableau de valeurs en réponses an array of values as response.
La longueur du tableau dépend directement de la valeur {sampleSize} et de la fenêtre temporelle définie par le {startDate} et {endDate} paramètres. Une fois qu’une fenêtre temporelle de référence a été définie, la valeur {sampleSize} tranchera cette fenêtre plus ou moins fréquemment modifiant ainsi par conséquent la longueur du tableau en réponse: plus le {sampleSize} moins la fenêtre temporelle sera découpée, ce qui entraînera moins d’éléments dans le tableau de réponse.
Il vaut la peine de regarder un exemple direct pour mieux expliquer ces concepts.
Example
Supposons que nous voulons représenter la tendance en temps réel de la puissance produite par un onduleur, au cours de la journée en cours (supposons que nous sommes à l’équinoxe de printemps). La meilleure solution est d’utiliser une API Timeseries, qui aura la structure générale suivante:
https://api.auroravision.net/api/rest/v1/stats/{power,frequency,wind,temperature,voltage,current,energy,kpis}/timeseries/12345678/{dataType}/{valueType}?{sampleSize}&{startDate}&{endDate}&{timeZone}
Dans la structure générique ci-dessus, nous savons que:
- La catégorie de ressources à viser est
{power}et, dans cette catégorie, le{dataType}à appeler est le; - Le
{valueType}à appeler est l’un desMaximum,MinimumetMoyenne(veuillez vous référer à l’analyse détaillée plus bas) ; - La fenêtre horaire est le jour de l’équinoxe de printemps, donc
{startDate}sera 20220321 et{endDate}sera 20220322 ;
Cela amène notre appel à prendre la forme suivante:
https://api.auroravision.net/api/rest/v1/stats/power/timeseries/12345678/GenerationPower/average?{sampleSize}&startDate=20220321&endDate=20220322&{timeZone}
Le paramètre {sampleSize} peut avoir les valeurs suivantes:
Min5: la fenêtre de temps est découpée toutes les 5 minutes, en prenant chaque échantillon enregistré sur Aurora Vision (voir page 1) ;Min15: la fenêtre temporelle est découpée toutes les 15 minutes, 3 échantillons Aurora Vision sont inclus pour chaque tranche ;Min30: la fenêtre temporelle est découpé toutes les 30 minutes, 6 échantillons Aurora Vision sont inclus pour chaque tranche ;Hour: la fenêtre temporelle est découpée toutes les 60 minutes, 12 échantillons Aurora Vision sont inclus pour chaque tranche ;Day: la fenêtre horaire est découpée chaque jour, 288 échantillons Aurora Vision sont inclus pour chaque tranche ;Month: la fenêtre temporelle est découpée chaque mois ;Year: la fenêtre temporelle est découpée chaque année.
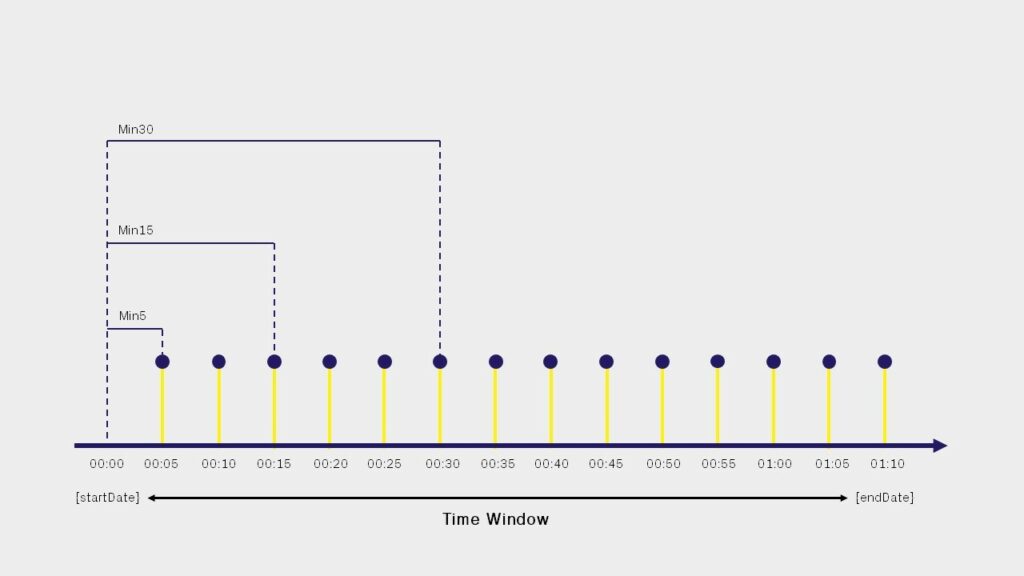
Puisque nous souhaitons représenter la tendance de puissance en temps réel, aussi souvent que possible, nous choisissons de définir {sampleSize} sur Min5 ( cela n’aurait aucun sens de saisir une valeur supérieure à celle de la fenêtre horaire choisie) et de définir le paramètre {timeZone} sur Europe/Rome :
https://api.auroravision.net/api/rest/v1/stats/power/timeseries/12345678/GenerationPower/average?sampleSize=Min5&startDate=20220321&endDate=20220322&timeZone=Europe/Rome
La réponse sera un tableau d’une certaine longueur dans lequel chaque élément sera toujours composé de la structure suivante :

Comme nous pouvons le voir, la réponse est composée de :
Start: représente l’époque, qui est la valeur de l’heure en UTC ; change selon letimeZone(différents fuseaux horaires auront des époques différentes pour la même valeur de puissance) et suit les tranches temporelles définies par lesampleSize;Unités: représente l’unité de mesure ;Valeur: représente la valeur.
Extrapolons un extrait plus large de la réponse :

Le champ start augmente d’élément en élément, passant d’une valeur de 1647875700 à une valeur de 1647876000 ; si nous faisons la différence entre les deux époques, nous obtenons exactement 5 minutes ou, en d’autres termes, la valeur que nous avons définie pour le paramètre sampleSize .
De l’époque 1647876000 les champs et start value Europe/Rome), l’échantillon auquel il est fait référence avec cette époque est dans le futur et, par conséquent, n’existe pas encore. En tant que tel, Aurora Vision ne fournit pas le champ au sein de l’élément ; cependant, sur un nouvel appel effectué après 16h20, il le fournira car il a été renseigné.
Le principe sur la présence/absence de certains champs dans les éléments de réponse d’une API timeseries (exprimé dans les dernières lignes de l’exemple ci-dessus) est d’une importance fondamentale : il ne s’applique pas uniquement dans le cas des futurs prélèvements, mais aussi et surtout en cas d’absence totale de données sur Aurora Vision. Cela permet d’apporter de la cohérence aux réponses obtenues des API de télémétries, car lorsque la valeur déposée est présente, cela signifie que cette valeur existe réellement sur Aurora Vision sinon elle ne serait pas présente.
Comme c’était le cas pour les appels agrégés, également pour les appels de séries chronologiques, le paramètre {valuetype} est d’une grande importance car il varie en fonction de la catégorie de ressources, donc de {dataType}, à obtenir et est également affecté par le {sampleSize}.
Pour un {dataType} appartenant à la catégorie {power,frequency,wind,temperature,voltage,current,kpis}, the {valueType} peut prendre trois valeurs différentes:
Maximum: renvoie la valeur maximale trouvée parmi tous les échantillons présents dans le temps{startDate}et{endDate}défini fenêtre, pour le{dataType};Minimum: renvoie la valeur minimale trouvée parmi tous les échantillons présents dans le temps{startDate}et{endDate}défini fenêtre, pour le{dataType};Average: renvoie la valeur moyenne de tous les échantillons présents dans la fenêtre temporelle{startDate}et{endDate}défini fenêtre, pour le{dataType};
REMARQUE: pour la catégorie kpis , les considérations ci-dessus ne sont valables que si les Power-Based KPIs sont appelés. Pour plus de détails, veuillez consulter OpenAPIs Swagger.
Regardons quelques cas d’utilisation, où nous considérons une installation ( entityID: 12345678 ) avec un seul onduleur enregistré ( entityID : 87654321 ):
Use Case 1
Je souhaite obtenir la puissance générée par l’onduleur en temps réel, toutes les 5 minutes, le jour de l’équinoxe de printemps. De cette façon, je peux tracer la tendance et effectuer une analyse spécifique dessus.
Analyse des Problèmes
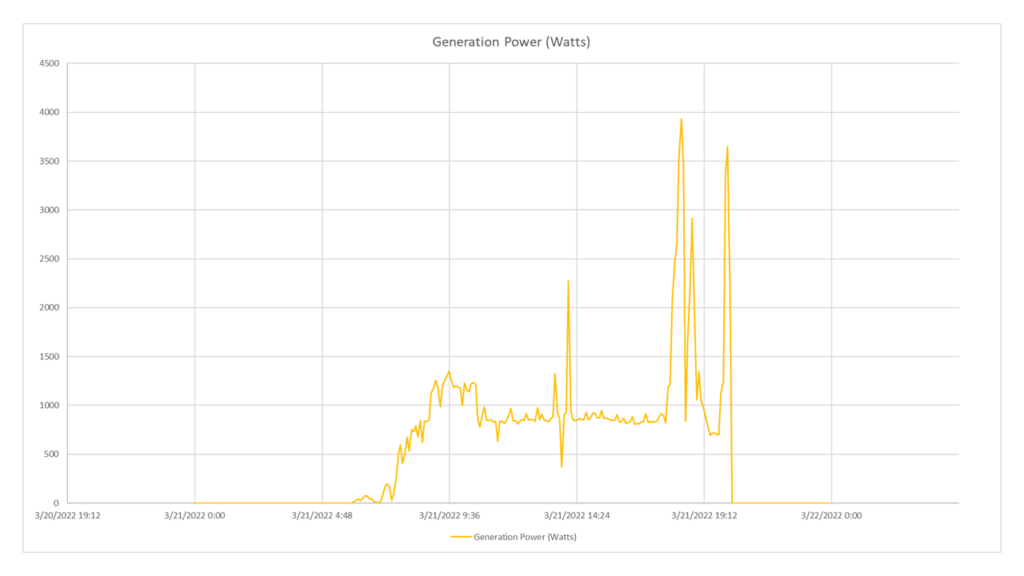
Considérant que le rapport entre l’usine et les appareils enregistrés est de 1:1, je peux indifféremment saisir l’entityID de l’un des deux. Je veux la puissance produite, je vais donc pointer les ressources de la catégorie power et demander la GenerationPower. Le paramètre sampleSize sera égal à Min5 , car je veux obtenir chaque échantillon. Le paramètre valueType peut être, dans ce cas seulement, défini indifféremment comme Maximum, Minimum ou Average car le temps la fenêtre est découpée de manière à avoir un seul échantillon pour chaque tranche et, par conséquent, aucune opération réelle ne fait la différence s’il y a un seul échantillon comme référence.
Request
GET https://api.auroravision.net/api/rest/v1/stats/power/timeseries/12345678/GenerationPower/average?sampleSize=Min5&startDate=20220321&endDate=20220322&timeZone=Europe/Rome
Charted Response
Use Case 2
Je veux obtenir la puissance moyenne générée par l’onduleur toutes les 15 minutes, le jour de l’équinoxe de printemps. De cette façon, je peux tracer la tendance et effectuer une analyse spécifique dessus.
Analyse des Problèmes
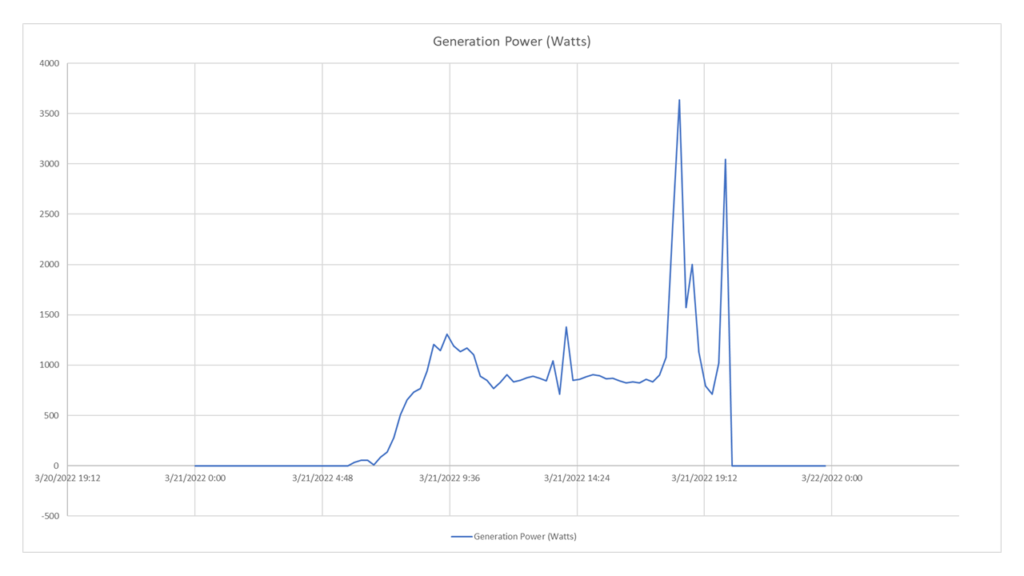
Considérant que le rapport entre l’usine et les appareils enregistrés est de 1:1, je peux indifféremment saisir l’entityID de l’un des deux. Je veux la puissance produite, je vais donc pointer les ressources de la catégorie power et demander la GenerationPower. Dans ce cas, le paramètre sampleSize sera égal à Min15. Le paramètre valueType doit être Average car la fenêtre temporelle est découpée de manière à avoir 3 échantillons pour chaque tranche et donc la moyenne est effectuée sur les 3 échantillons appartenant à chaque tranche.
Request
GET https://api.auroravision.net/api/rest/v1/stats/power/timeseries/12345678/GenerationPower/average?sampleSize=Min15&startDate=20220321&endDate=20220322&timeZone=Europe/Rome
Charted Response
Pour un {dataType} appartenant à la catégorie {energy,kpis}, le {valueType} peut prendre deux valeurs différentes:
Cumulative: renvoie la dernière valeur cumulée disponible dans la fenêtre temporelle{startDate}et{endDate}défini fenêtre, pour le{dataType};Delta: renvoie la différence entre la dernière et la première valeur cumulée disponible dans le{startDate}et{endDate}défini fenêtre, pour le{dataType};
REMARQUE: pour la catégorie kpis , les considérations ci-dessus ne sont valables que si les Energy-Based KPIs sont appelés. Pour plus de détails, veuillez consulter OpenAPIs Swagger.
Regardons quelques cas d’utilisation, où nous considérons une installation ( entityID: 12345678 ) avec un seul onduleur enregistré ( entityID : 87654321 ):
Use Case 1
Je souhaite obtenir l’énergie générée par l’onduleur en temps réel, toutes les 5 minutes, le jour de l’équinoxe de printemps ; afin de tracer la tendance énergétique.
Analyse des Problèmes
Considérant que le rapport entre l’usine et les appareils enregistrés est de 1:1, je peux indifféremment saisir l’entityID de l’un des deux. Je veux l’énergie produite, je vais donc pointer les ressources de la catégorie energy et demander la GenerationEnergy. Le paramètre sampleSize sera égal à Min5 , car je veux obtenir chaque échantillon. Le paramètre valueType sera égal à delta car la fenêtre temporelle est découpée de manière à avoir un seul échantillon pour chaque tranche et donc la différence entre les échantillons fournira l’énergie réellement produite en 5 minutes.
Request
GET https://api.auroravision.net/api/rest/v1/stats/energy/timeseries/12345678/GenerationEnergy/delta?sampleSize=Min5&startDate=20220321&endDate=20220322&timeZone=Europe/Rome
Response

Use Case 2
Je souhaite obtenir l’énergie générée par l’onduleur pour chaque jour de la semaine de l’équinoxe de printemps, afin de tracer la tendance énergétique hebdomadaire.
Analyse des Problèmes
Considérant que le rapport entre l’usine et les appareils enregistrés est de 1:1, je peux indifféremment saisir l’entityID de l’un des deux. Je veux l’énergie générée chaque jour de la semaine de l’équinoxe de printemps, donc je vais pointer les ressources de la catégorie energy et demander la GenerationEnergy. Le paramètre sampleSize sera égal à Jour, car je souhaite découper la fenêtre horaire chaque jour de la semaine. Le paramètre valueType sera égal à delta car la fenêtre temporelle est découpée de manière à avoir la différence entre le premier et le dernier échantillon de chaque jour de la semaine (fenêtre horaire).
Request
GET https://api.auroravision.net/api/rest/v1/stats/energy/timeseries/87654321/GenerationEnergy/delta?sampleSize=Day?startDate=20220321&endDate=20220327&timeZone=Europe/Rome
Response
